










ご担当者が翻訳で、「あっ、しまった!」とならないためのコツ 。
「翻訳は、お客様のデータ『資産』です!」
初めに
英語には、”Translation Assets”ということばがあります。翻訳のアセット、つまり「翻訳資産」です。翻訳が資産になるとは、ちょっと変わった発想だと思います。ちなみに、プロパティ(property)ということばも「資産」を意味しますが、どちらかというと土地や建物などのように物理的な形をもつものを指し、アセット(asset)は、それらの財源になるような金銭、株式、債券、知的財産など経済的な価値を持つもの全般を指します。実は、翻訳もそのような資産の一種ということになるのです。
翻訳のどういったところが「資産」なのでしょうか。そして、もし資産だとした場合、翻訳ならではの資産活用についてもご説明します。

一般的な資産
わたしたちは「資産」と聞くと、どんなイメージを浮かべるでしょう。たとえば車や土地建物のように金額的に大きな物になると、転売価値が生じます。不動産や中古車市場は、その価値の売買で成り立っています。特に希少価値の高い車や人気物件になると、元の値段以上に価値が上がることも珍しくありません。
逆に世間のニーズが無ければどんな資産でも価値は下がり、元本割れするリスクを伴います。維持費ばかりかかって、安値のため売るに売れない「負(不)動産」なんていう皮肉めいた言い方もありますから、「資産」にはリスクも伴います。しかし他者からのニーズがあれば、持っている人に何かしらの経済的な価値をもたらすのが「資産」です。初め(投資時)よりも高い価値を生み出すものを指して「資産」と呼ぶのです。
車や土地といった具体的な形を持つもの(有形資産)以外にも、形を伴わない「無形資産」と言われるものも多くあります。そんな無形の資産の一つが「データ」です。
現代は、ネット上に存在する膨大なデータを利活用することで、あらゆる企業の経済活動が成り立っています。たとえばSNSのユーザーは、書きこみや画像をアップしたり、掲載広告を閲覧したりすることで無意識にまた自発的に個人に関するデータを企業に提供しています。運用元のソーシャルメディア企業は、そうして集めた固有のユーザーデータ(年齢、性別、居住地はもちろん、趣味趣向などの属性)を分析し、各個人に焦点をあてた広告を提供することで、高い広告収入を得ています。膨大な個人データを資産として活かしていることになります。 また、昨今かまびすしい生成AIの知能の源(資産または資源)は、ネット上に蓄積された膨大なデータです。そのデータをある意味、自律的に活用できるのが生成AIになります。生成AIのユーザーは、あらゆるトピックに関するさまざまな質問内容やそのパターンをAIに与え、AIはそれを学習することでも自律的にますます知能を高めていきます。
つまり「データという無形資産」は、インタラクティブな(双方向)コミュニケーションによって内容が更新または蓄積され続け、それを活用することで提供元に大きな価値をもたらす性質があることがわかります。
※ (資産の特長まとめ)
- 初め(投資時)よりも高い価値を生み出してくれる (価値の増大化が可能)
- 内容が更新・蓄積され、それを利活用(再投資)することで一層大きな価値を生み出す(持続的な再投資が可能)
翻訳の資産とは
それでは「翻訳資産」と言った場合、これらの特長は当てはまるのでしょうか。まず、「始まり(投資)」があるとすれば、それは継続するものでないといけません。
時限的な一過性または即時性のものではなく、継続して「再利用(再投資)」されることが前提です。「翻訳資産」の特性は、ほとんどが文脈をもつ「テキスト(文字)データ」であることです。
膨大な翻訳テキストデータを全て記憶し、必要に応じて再利用する。そのようなことが果たして可能でしょうか。これを可能にするため、私たちは「翻訳資産」として次の三つのものをお客様に提供しています。
- 用語集
- 翻訳メモリ
- スタイルガイド
これら資産の管理ルール
「翻訳(テキスト)」を資産化するには、統一性や一貫性を持たせ、再利用しやすいように管理する必要があります。
それぞれについて説明します。1の「用語集」は”Glossary(グロサリー)”とも言われますが、お客様固有の用語辞書になります。この固有の辞書が無いと、どの言葉が「用語」なのかわからないことになります。「用語」が決まっていないため、AIや人が翻訳するときに、同じ表現で統一されなかったり、全く的外れの別の表現ばかりになってしまったりして、「用語表現の統一」という望ましい結果が得られません。翻訳の再利用どころではなくなってしまいます。逆に「用語集」という枠(基準)があることで、翻訳の品質に一貫性が出て、その再現の重要性も増すことになります。
例えば、税務用語として「配偶者控除」というものがあります。国税庁のサイトでは、「配偶者控除」の英語は"Exemption for spouse"と訳され、統一されていますが、汎用的な翻訳AIが翻訳すると、"Spouse Deduction" "Marital Deduction" "spousal deduction" "spouse deduction" という風に、大小文字ふくめて記述や表現にバリエーションが出てきます。意味する内容は一緒ですが、一つの文書内に、これらの表現か混在したとしたら、どうでしょうか。これ以外の用語も同様にいくつものバリエーションで表現されているとすると、読み手が混乱し、途中で読むのをやめてしまうかもしれません。言葉にバリエーションを持たせるというか、場面に応じて適切な言葉を選択するのは、文章が味わい深く豊かになるため、総じて良いことではあります。しかし、一般的では無い、むしろ専門的な用語として認識させたい特定の言葉は、一つの表現に絞り込んだ方が話の筋を追い易く、読み手の注意を引いて理解が深まることになります。
また、この「配偶者控除」の英語バリエーションを元に、さらに他のいくつかの言語に翻訳するとどうなるでしょう。もし言語ごとに表現のバリエーションが増えてしまうとしたら、表現の統一どころではなく、もはや収拾がつかなくなるのではないでしょうか。校正者が後から手直しして統一するとしても、訂正の時間とコストが余計にかさむため、とても「翻訳資産」とは呼べなくなり、逆にマイナス資産化してしまいます。
翻訳メモリ
2 の「翻訳メモリ」(Translation Memory)は、対訳データベースを指して表す専門用語です。基本的に1の「用語」よりはもう少し長いもの、主に「文」などの単位で切り分けられたものが中心となります。例えば、ある任意の日本語の文と、その日本語文の対訳になる外国語の文とを一つのセット(対-つい)にしてデータベース化したものになります。これを「翻訳メモリ」と呼んでいるのです。
ことば遣いや文章全体の調子(文体)には、書く人の個性(クセ)が投影されがちで、翻訳に関しても同じことが言えます。もちろん文書種類に応じたふさわしい文体や表現であることは最低限の水準ですが、それでも書く人や翻訳する人の個性が出てしまうものです。もし、過去の文書を部分的に改訂する必要があって、書き手や翻訳者(AI)が以前と変わるとしたらどうでしょう。そのままではおそらく、書き手のクセや文体がいろいろと混ざってツギハギのような文書となり、一貫性が損なわれて、大変読みにくい文書となることでしょう。
翻訳メモリが使われる理由
「翻訳メモリ」はこれを防ぎ、改訂される文書がツギハギ状態にならないようにする役割を果たします。もし毎回、新しい書き手や翻訳者が全体を通して手直ししないといけないとすると、ムダな時間やコストがかかってしまい、非効率的です。しかし、以前使われた「用語」も含め、「言い回し」や「文体」がデータベースになっていると参照しやすく、簡単に流用がきいて、人の手による修正と比べて、より一層、文書の一貫性や品質を保つことができるようになります。「翻訳メモリ」というデータベースがあると、効率的な文書改訂(翻訳)をすることが可能になるのです。
内容的な修正を効率化する「翻訳資産」の役割について、ご説明してみました。わたしたちは、このようにして、文書品質の安定化・向上化を図り、データ資産を利活用することで効率化と余計なコストの削減を実現化しています。
スタイルガイド
ただし、そのように利活用される「翻訳資産」ですが、最終的にはさまざまな形を伴ってお客様に利用されることになります。例えば、印刷物やホームページなど、具体的に目に見える形を取る場合が通常です。(ナレーション音声などは、厳密には文字ではありませんが、読み上げ原稿としては、一旦は文字化されます。)
そこで、3の「スタイルガイド」が必要になってきます。理由は主に三つあります。
(理由1) 文書構造
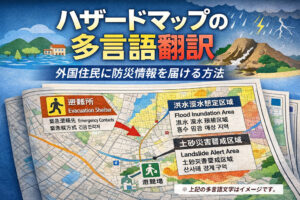
印刷物やホームページなどの文書は、大抵、構成が把握しやすいように見た目が「構造化」されているという点が重要です。何がタイトル(大見出し)で、中見出し・小見出しはどれか、ヘッダー、フッター、本文はどれか、どのように他と区別されているのか見た目で判断できるように、表示上で何らかの工夫が施されているはずです。段落項目番号や、文字の大きさの違いなどなど、見た目でわからないと文書全体の構成がわかりにくく、内容の理解に支障をきたしてしまうからです。翻訳されたデータを正しく配置するには、各言語に合わせてこの「文書構造」を揃えておく必要があります。
(理由2) 文字数の違い
せっかく効率的に変更した(翻訳)テキストデータでも、最後にはきちんと印刷物なり、ホームページなりに正しく「レイアウト配置(またはデザイン)」されなければいけません。言語によっては、文字数が大幅に違ったりします。文字数の違いを見ると、大雑把に以下のような等式が成り立ちます。
- 中国語文字数 = 日本語文字数の約0.8倍
- 英語文字数 = 日本語文字数の約1.5~2倍
- フランス語やアラビア語文字数 = 英語文字数の約1.3倍
同じ意味内容を伝えていても、そもそも言語ごとに文字数が違うため、配置(レイアウト)には工夫が必要になります。
(理由3) 表記法に関する文化風習の違い
さらにアラビア語等の「右横書き言語」は、文章は右から左へ(数字は左から右へ)表記するという特徴が、他のほとんどの言語と大きく異なりますが、私たちの日本語でも、元が縦書き表記の場合、他の言語ではどうするかといった問題にぶつかります。特に、表(ひょう)で組まれたレイアウトの中で縦書きがよく使われますので、気を付けないといけません。
また、上記の理由2では見慣れた「※ (コメ印)」や「~ (波ダッシュ)」などの記号を用いていますが、これ自体は日本国内でのみ通用し、海外では用いられないため、うっかり使うと意図した意味が伝わらなくなってしまうことがあります。細かい点では、数字のカンマの用い方も国によって異なるのです。
- 英米日中など: 1,000,000 (1 million) …3桁ごとにカンマ(,)
- フランス: 1 000 000 (1 million) …3桁ごとに空白スペース
- ドイツ: 1.000.000 (1 million) …3桁ごとにピリオド(.)
これらのレイアウトや記号表記に関する決まり事(ルール)を前もって決めておかないと、せっかく翻訳を効率よく正しく行っても、印刷やホームページになった途端に、意図したレイアウト通りでなかったり、最悪な場合、文章のどこかが欠落していたり、数値記号などの表記法を間違えていたりといった大きなトラブルに繋がっては元も子もありません。
記号表記をどうするか、言語が変わったとしても同様のレイアウトで印刷物やホームページを作成するにはどうするか、といった問題点に対処するのが、「スタイルガイド」になります。
まとめ
最初に、「価値の増大化が可能」や「持続的な再投資が可能」という点を資産の特徴として定義しました。この2点を完結させるためには、データ資産の入力(翻訳)から出力(レイアウト)までを網羅して効率化させないと不十分で、どれかが欠けていては「資産」の価値が目減りしてしまうことになります。翻訳は、「翻訳して終わり。」ということは少なく、いつも必ず何かの形をとるということを念頭に、最終形をイメージして工夫することが全工程における効率化にとって、重要になってきます。
わたしたちは、翻訳のデータベースを構築した後に、効率的に且つ正しく内容を配置するところまでを、翻訳というデータの資産化に重要なことと認識して、「翻訳資産」という「データ資産」として、お客様にご提供しています。
AIが翻訳するとしても人が翻訳するとしてもそれは出力スピードの差が出るだけのことで、品質の確認と保証は第三者が客観的に行なわないといけません。そういう意味で、「翻訳」を評価するということは、データの意味内容を判断評価する非常にアナログな分野と言えます。その意味内容を判断評価する手間や回数を削減する工夫こそが、翻訳のDX(デジタルトランスフォーメーション)につながり、時代の要請に応じることにつながっていくものと確信しています。